A report from the 9th International AAAI Conference on Web and Social Media (ICWSM), Oxford, Spring 2015
Over four days in Oxford, the 9th International AAAI Conference on Web and Social Media (ICWSM) took place, at the Mathematical Institute. The event sponsors include Facebook and Yahoo and it’s not a huge conference, just over 250 researchers in computer science and social science who gather to “share knowledge, discuss ideas, exchange information, and learn about cutting-edge research in diverse fields with the common theme of online social media.”
I’d stumbled upon the conference whilst reading articles for my PhD. The conference is often in far flung locations (2016 it’s Cologne, 2017 it could be Montreal, Doha or Seattle) and discovered it was taking place in the UK. I managed to attend just one day and sat through 20 presentations. Here’s what I discovered.
Beware of trolls
Justin Cheng of Stanford University and others are researching ‘Antisocial Behavior in Online Discussion Communities’. Effectively, he’s seeking trolls. The research shows that it’s possible to predict whether a user will be banned (not all trolls are banned) and also illustrates antisocial (or troll) behaviour. This has great implications for those managing online communities – in the future it could be possible to convert the model into a ‘troll alert’ for community managers, to manage a situation, before it went out of control.
Smelly Maps
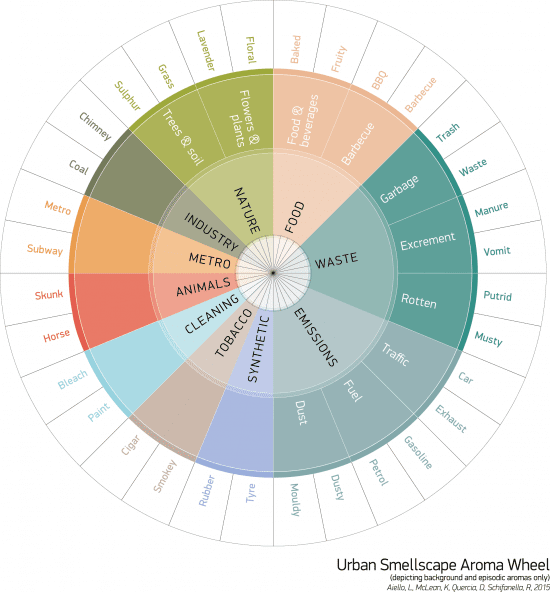 This presentation opened a new dimension – using the sense of smell within urban planning! The above image is based on the research on social media.
This presentation opened a new dimension – using the sense of smell within urban planning! The above image is based on the research on social media.
Daniele Quercia, Rossano Schifanella, Luca Maria Aiello and Kate McLeans are working on ‘The Digital Life of Urban Smellscapes’. Teams of people in London and Barcelona explored urban areas and plotted out the smellscape. The idea is that this could assist urban planners when designating areas for specific use.
Imagine future planning applications being submitted with smellscape information!
Quora predictions
Suman Kalyan Maity and others are exploring Quora and how it’s possible to predict topic popularity. They gathered data over four years using web-based crawl
This could have a useful business application as if you knew a thread was about to start focused on your business sector, you could jump in and take part in the conversation.
Social ad targeting
Jilin Chen and Eben Haber and others are working on targeting ads across social networks based on personality type. They created a Twitter account @TravelersLikeMe and focused on Twitter users visiting New York City (NYC), because they found NYC among the most popular destinations mentioned on Twitter. Where they found Twitter users who said they were planning to visit New York in the near future, the @travelerlikeme account sent a reply tweet recommending various activities and encouraging a sign-up to a web link. If the user followed them back, they sent them a direct message.
The research showed that this specific targeting has had an impact on the open rates. My experience with social ads is that the open rates tend to be low (0.2% to 2%) but it’s with a more focused audience. The idea that you could profile Twitter users and start conversations, based on their personality type.
Research panels
One of the greatest challenges conducting research is finding participants. Several USA-based researchers get around this using Amazon’s Mechanical Turk (it’s only available in the US) and if you haven’t come across this before, you pay a set fee for a specific task. Fees range from a few cents to a few dollars, depending on the time required, complexity, preferred audience background – you set the rate and people decide whether or not to take on the task. I imagine this is a well-suited system for students to each some cash (although you’d need to perform quite a few tasks to generate a real income). As an example, the researchers on @travelerslikeme used Amazon’s Mechanical Turk for part of their initial research and paid their respondents 50 cents and estimated the work took six minutes.
Another solution was shared by Jaime Arguello from the School of Information and Library Science at the University of North Carolina at Chapel Hill, when he was discussing ‘Predicting Speech Acts in MOOC Forum Posts’, another US university has created Volunteer Science.
Volunteer Science is an online semi-gaming environment. Researchers can set up surveys, forums and panels and recruit volunteers to participate. Possibly more exciting than playing Candy Crush or Angry Birds and at the same time contributing to new scientific discoveries 🙂 And if you’re curious, you can sign up and join in!
Ethics in online research
The social networks have eyes and ears as well as a host of data that you can extract. At this stage I should add #EthicsAlert as there are debates about whether it’s ethical to use online data.
If you want to know more, the ‘gold standard’ of ethics policies is widely accepted as that used by the British Psychological Society (see http://www.bps.org.uk/what-we-do/ethics-standards/ethics-standards for the full list of options).
Extracting online data
The Twitter API enables extraction of tweets, other software programmes allow you to check hashtags, followers and more. Twitter’s API is said to be clunky and there are usage limitations and several researchers use more than one PC to get around the time limiter as it could take months to extract the data needed.
One useful tool mentioned was CrowdTangle which allows researchers (and companies) to harvest data from a range of sources. It’s still in beta and you register your interest and sit back and wait for your invitation to arrive (there’s a waitlist).
Another useful Twitter tool, which provides instant analytics is Tweet Archivist which allows you to export your data into other systems, for example excel and beyond. This shows the top users, mentions and related hashtags.
There are challenges with all Twitter data tools as sometimes details are recorded twice, so for example you get duplicate users. One researcher commented that the data is around 70% accurate. This depends on your search times and date range.
Release the data!
Dr David Jurgens from the Network Dynamics Lab at McGill University is working on understanding populations, location, and language. He implored researchers to share and release their data! Remembering that this conference has a computer science foundation, this was a clarion call to others in different sectors. Certainly in marketing we guard our data and the idea of sharing it is very scary. However, the ICWSM makes available large data sets that researchers can use. Sign up, become a member and gain access!
Have you attended an academic or research conference about digital marketing lately and would like to share the findings? Do tweet us @SmartInsights and @AnnmarieHanlon as we’d love to spread the word about latest tools and techniques.





